Load balancer overview
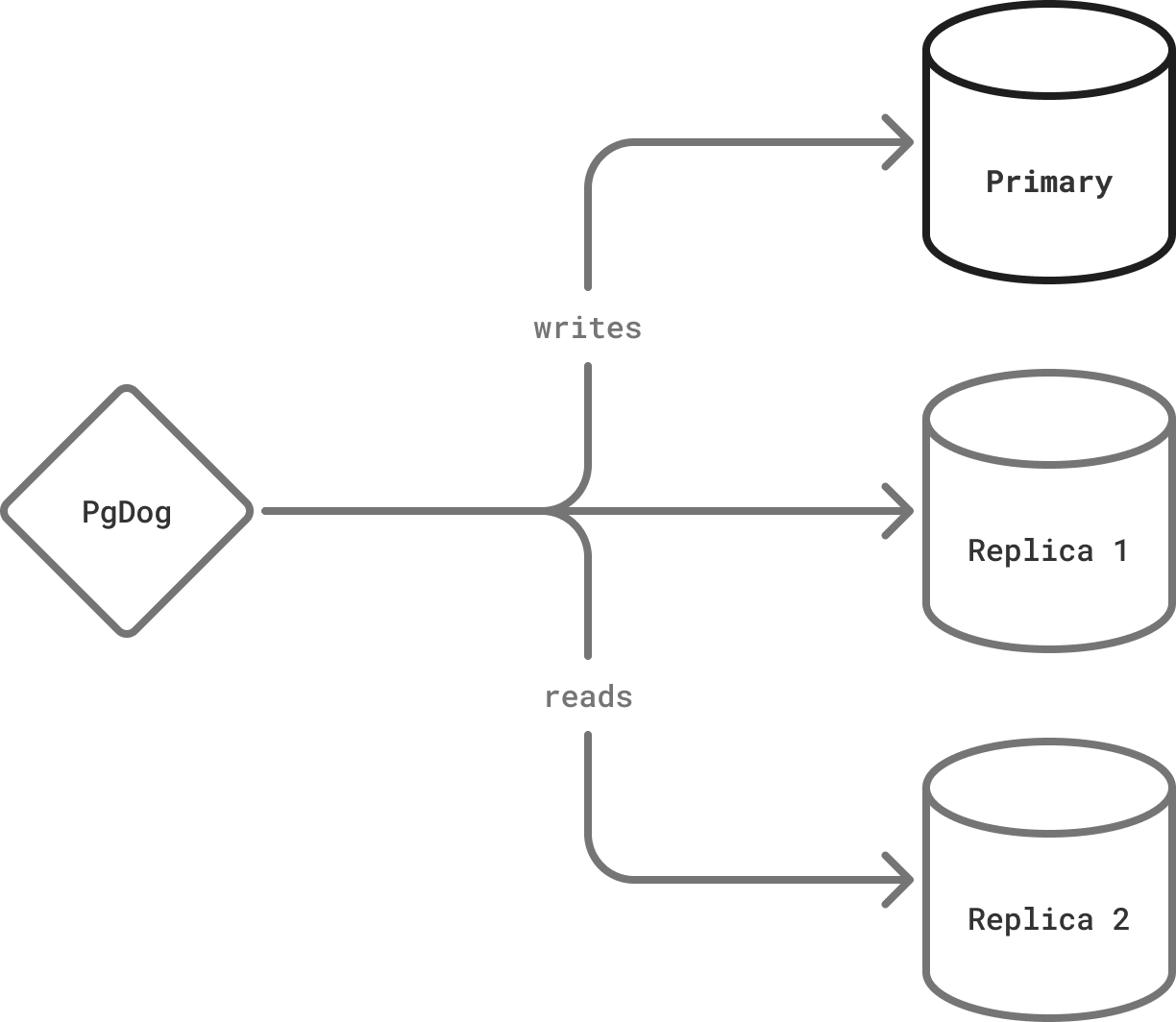
PgDog operates at the application layer (OSI Level 7) and is capable of load balancing queries across multiple PostgreSQL replicas. This allows applications to connect to a single endpoint and spread traffic evenly between multiple databases.
How it works
When a query is sent to PgDog, it inspects it using a SQL parser. If the query is a read and the configuration contains multiple databases, it will send that query to one of the replicas. This spreads the query load evenly between all database instances in the cluster.
If the config contains a primary, PgDog will split write queries from read queries and send writes to the primary, without requiring any application changes.
Algorithms
The load balancer is configurable and can route queries using one of the following strategies:
- Random (default)
- Least active connections
- Round robin
Choosing the right strategy depends on your query workload and the size of replica databases. Each strategy has its pros and cons. If you're not sure, using the random strategy is usually good enough for most deployments.
Random
Queries are routed to a database based on a random number generator modulus the number of replicas in the pool. This strategy is the simplest to understand and often effective at splitting traffic evenly across the cluster. It's unbiased and assumes nothing about available resources or individual query performance.
This algorithm is used by default.
Configuration
Least active connections
PgDog keeps track of how many connections are active in each database and can route queries to databases which are less busy. This allows to "bin pack" the cluster with workload.
This algorithm is useful when all databases have identical resources and all queries have roughly the same cost and runtime.
Configuration
Round robin
This strategy is often used in HTTP load balancers (e.g., like nginx) to route requests to hosts in the same order as they appear in the configuration. Each database receives exactly one query before the next one is used.
This algorithm makes the same assumptions as least active connections, except it makes no attempt to bin pack the cluster and distributes queries evenly.
Configuration
Reads and writes
The load balancer can split reads (SELECT queries) from write queries. If it detects that a query is not a SELECT, like an INSERT or an UPDATE, that query will be sent to primary. This allows a deployment to proxy an entire PostgreSQL cluster without creating separate read and write endpoints.
This strategy is effective most of the time and PgDog also handles several edge cases.
SELECT FOR UPDATE
The most common edge case is SELECT FOR UPDATE which locks rows for exclusive access. Much like the name suggests, it's often used to update the selected rows, which is a write operation.
The load balancer detects this and will send the query to a primary instead of a replica.
CTEs
Some SELECT queries can trigger a write to the database from a CTE, for example:
WITH t AS (
INSERT INTO users (email) VALUES ('test@test.com') RETURNING id
)
SELECT * FROM users INNER JOIN t ON t.id = users.id
The load balancer will check all CTEs and, if any of them contain queries that could write, it will route the entire query to a primary.
Transactions
All multi-statement transactions are routed to the primary. They are started by using the BEGIN command, e.g.:
While often used to atomically perform multiple changes, transactions can also be used explicitly route read queries to a primary as to avoid having to handle replication lag.
This is useful for time-sensitive workloads, like background jobs that have been triggered by a database change which hasn't propagated to all the replicas yet.
Note
This behavior often manifests with "record not found"-style errors, e.g.:
Configuration
The load balancer is enabled automatically when a database cluster contains more than one database, for example:
[[databases]]
name = "prod"
role = "primary"
host = "10.0.0.1"
[[databases]]
name = "prod"
role = "replica"
host = "10.0.0.2"
Allowing reads on the primary
By default, the primary is used for serving both reads and writes. If you want to isolate these workloads and have your replicas serve all read queries instead, you can configure it, like so:
Read more
Health checks
Learn how PgDog ensures only healthy databases are allowed to serve read queries.